Jonathan Keane, PhD
Some older projects that some might still find useful — most are from my academic days.
Past Projects
A selected list of past and current projects.
Police Early Intervention System
project webpage | project github repo
Adverse interactions between police and the communities that they are tasked with protecting are an ongoing problem in the United States. The worst of these interactions have fatal consequences, but even interactions that don’t result in death do irreparable harm and are devastating to the citizens involved. Preventing these interactions is critical to a just society and is one step in building trust between communities and police.
During the summer of 2016, I was a data science fellow with Data Science for Social Good. I worked on a team that developed an early intervention system in partnership with the Metropolitan Nashville Police Department. This system is designed to identify police officers who are at high risk of having an adverse incident; so that the department can step in and provide additional training, resources, counseling, or take other appropriate actions in order to try and prevent adverse incidents from happening in the first place. Although it would be impossible to predict and prevent all negative interactions between police and the public, an early intervention system is one piece of a broader movement for criminal justice reform that can help lead to fewer negative interactions and better outcomes for the communities that the police serve.
In addition to developing a predictive model for our partner department, we also worked closely with another team who was working with the Charlotte Mecklenburg Police department. Together we developed a pipeline, database schema, and model that is department-independent. This added layer of collaboration is a key proving ground that the systems we developed can be implemented not just at one department, but, given the right data, almost any department in the country.
We used 5 years of internal department data (including arrest records, dispatches, patrol areas, internal and external discipline, citizen complaints, &c.) as inputs to our model. For each officer, we made a prediction (which can also be thought of as a risk score) of how at risk of being involved in an adverse incident that officer is over the next year. Our best performing model (a variation on random forests) correctly identified 80% of officers who went on to have an adverse incident (during our test period), while only requiring intervention on 30% of officers in the department. This is a drastic improvement over using the current state of the art in most police departments (a threshold-based flagging system): which would have needed to intervene on 67% of the department for the same level of accuracy.
Since the summer, the Center for Data Science and Public Policy has continued work with both police departments and is in the process of implementing these models. This is the first data-driven early intervention system of its kind to be implemented in any department in the United States.
Software
Some interesting and hopefully helpful tools for others — mostly from my academic days
MocapGrip
MocapGrip is a complete data processing and analysis pipeline R package. MocapGrip contains a full pipeline for motion capture data collection, from initial data processing to statistical modelling and report generation. The package includes functions to check human annotated data for consistency and errors, as well as a flexible analysis and reporting system for use by novice users.
This was my first large-scale foray into building a stand-alone R package. For a number of reasons, I adopted a test-drive development approach to this package. Being test driven allowed me to better address (and ensure that I was reliable in addressing) data validation as well as providing feedback to users when there were errors was consistent and accurate. As the project grew, the number of possible edge-case errors exploded. Testing each one manually was unsustainable and error-prone. Whereas, using unit (and integration) tests through the testthat package being constantly run using travis ci .
Pyelan
I’ve developed pyelan, a python module that allows for eas[y | ier] extraction and manipulation of annotation data from elan files. Although this is a work in progress, some core functionality has been implemented. Pyelan can read, write, and preform some manipulations of eaf files. Pyelan now also allows for linking csv files to be viewed in the timeseries viewer. Please feel free to use, fork, submit issues, and submit pull requests.
The Articulatory Model of Handshape
For my dissertation, I implemented a computational model of the phonetics-phonology interface, that I call the Articulatory Model of Handshape. The implementation is as the amohs python module. This module not only implements automatic translation from phonological features to various types of phonetic representations (including joint angle targets), but it also uses an external library to render 3d images of hands.
The Articulatory Model of Handshape uses a slightly modified version of Brentari's 1998 Prosodic Model of handshape for a phonological representation of handshape. It than provides representations for phonetic specifications either as tract variables (at a categorical level), and as phonetic joint angle targets (a continuous level) for handshapes. Using these representations, comparisons between handshapes can be made deriving a theory-driven metric of handshape similarity.
On top of the computational implementation described above, the module uses an external library, LibHand to render images of synthesized handshapes. Currently, the model only renders isolated handshapes, but in the future could be extended to sequences of handshapes (including transitions), that is, video of handshapes moving over time. Because they are based on representations that can be linked to multiple levels of phonetics and phonology, these videos could include information about coarticulation (contextual dependencies) of the kind that was demonstrated in my dissertation.
At the time that I was trying, LibHand failed to compile on modern versions of OS X. I help maintain a repository that includes the changes needed to compile LibHand on modern linux, OS X, and windows systems. Compiling via homebrew is possible, with some alterations to ogre as well.
SLGloss LaTeX package
In collaboration with Itamar Kastner, I’ve helped developed the SLGloss LaTeX package to make it easier to typeset sign language glosses. It has three main features:
- It typesets sign glosses in smallcaps to integrate typographically with surrounding text, as well as allows for non-manual markings over specific constituents.
- It typesets fingerspelled words in small caps with hyphens between the letters
- It typesets lists of individual fingerspelled letters with hyphens on either side.
Fflipper
I’ve developed fflipper, a python module that allows for extraction of clipped videos based on the annotations extracted from an elan file.
asl fingerspelling chart
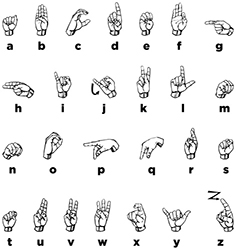
After seeing many charts that were licensed and reproduced with permission, I decided to recreate a fingerspelling chart and release it using a very liberal content license so researchers and educators that need this chart can use it (nearly) freely. The handshapes are based on the font from David Rakowski.
There a few problems with this chart. The biggest problem is that the orientation of many letters is altered to show the configuration of the fingers. In reality, all of the handshapes are made with the palming facing out, away from the signer with the exception of -g- (in, towards the signer), -h- (in, towards the signer), -p- (down), -q- (down) and the end of -j- (to the side)
Download the full sized, completely vector-based pdf version.

This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.
Better type for LaTeX
In the pursuit of better typography for LaTeX I’ve found a couple of good walkthroughs, and a couple of invaluable tools. All of the following have been tested on TeX Live 2009, 2010, and 2011 on both OS X 10.5, 10.6, and 10.7.
Minion Pro
I’ve created a bash script that installs Minion Pro to a local TeX Live tree with very little user intervention.
otfinst.py
John Owens has developed a great python tool that installs many OpenType fonts. The only stumbling block I found besides some font incompatibilities was assigning (making up) Berry names to the fonts that I wanted to install, which have to be added to the script. I have made up names for the following that seem to adhere most of the conventions. If anyone knows of more widespread names for these typefaces, please let me know.
- ‘Neutraface Text’ : ‘fne’
- ‘Neutraface Display’ : ‘fn3’
- ‘Gotham’ : ‘fg7’
- ‘Gotham Rounded’ : ‘fg8’
Hardware
I dabble in hardware development (really, mostly hacking existing products to do things I find useful).
Button board
Through the process of collecting various kinds of psycholinguistic data, I found the need to have a versatile, inexpensive feedback system for participants to use in order to interact with a computer during the course of an experiment. Although button boxes exist already, they are typically very expensive, and not of the form factor we desired for use in experiments.
To solve this, I developed a button board based on a Teensy 2.0 microcontroler and a in conjunction with momentary switch (e.g. Infogrip’s Specs Switch). The microcontroller is flexible enough to provide the computer with virtually any type of usb input possible when one of up to 4 buttons are pressed.
Kindle weather and cta arrival times display
After seeing a number of people make various persistent display devices with kindles, I decided that what I really needed was a display for weather as well as various cta arrival times near my apartment.
I developed a setup that grabs weather from wunderground or forecast.io, as well as arrival times for a limited number (5 currently, due to space restrictions of the kindle) of cta stops and stations. Then displays the arrivals persistently, and cycles through: current weather conditions, a 12 hour forecast, and a 5 day forecast.
Not content to just tack a kindle on the wall, I built a wood frame using a laser cutter to house the kindle and reroute the usb cable for charging.

Academic Research
I was a postdoctoral scholar at the Center for Sign, Gesture, and Language at the University of Chicago from 2014 to 2016. Previously, I worked as a research assistant in the Sign Language Linguistics Lab as well as the Chicago Language Modeling Lab. I have many research interests, particularly articulatory phonetics and phonology, morphology, and computational approaches to each. I have worked on a number of projects involving sign language phonetics and phonology, how perception and action influence gesture, and how gesture and sign languages interact.
Broadly speaking, I’m interested in how humans use their bodies to communicate both linguistically and non-linguistically. My primary focus is on how signers (people who use sign languages) use their body, arms, and hands in linguistic systems. How are the infinite number of possible configurations for a given articulator divided into meaningful groups (ie phonological units)? How much variation is allowed within these groups? What are the factors that contribute to this variation?
Since the fall of 2009, I’ve been working with a research group consisting of researchers who specialize in linguistics, speech and language processing, and computer vision, with the goal of developing automated sign language recognition tools. This collaboration fostered my interest in the phonetics of sign languages. I hope to continue to develop models and tools that contribute both to our knowledge of phonetics generally, and inform automatic recognizers of fingerspelling.
For a current list of my publications please see my publications.
American Sign Language (asl ) fingerspelling
Fingerspelling is used anywhere from 12 to 35 percent of the time in asl , (Padden and Gunsauls, 2003 ) and as such should not be set aside as extralinguistic. There has only been a small amount of information put together on the phonetics of fingerspelling. The only work on fingerspelling phonetics explicitly that I’ve found is (Wilcox 1992 ) as well as (Tyrone et al. 1999 ).
I’m especially interested in how contextual variation can be modeled based on linguistic (eg articulator activation, phonological features) as well as non-linguistic (eg physiological) factors. To test theories of this variation (as well as others about phonetics, phonology, and their interface), I study how signers produce asl fingerspelling. Studying fingerspelling provides opportunities to find contextual and time-conditioned variation in handshape that are relatively limited in signing. This work builds on phonological systems of sign language production, but with a detailed focus on the specific aspects that make up handshapes in asl .
My work continues to explore fingerspelling production. I am continuing to model handshape and temporal variation that was the focus of my dissertation. I’m also involved in projects that look at how native signers as well as second language learners perceive and comprehend fingerspelling, and especially what factors contribute to successful fingerspelling comprehension; in projects that look at how handshape similarity can be quantified and tested.
I use a variety of methods including annotated video data and instrumented capture to generate large, robust, quantitative sets of data. Similar methods have a (relatively) long tradition in spoken language linguistics, however they are only beginning to be used to look at signed languages. My work is supported in part by nsf 1251807.
Dissertation project
My dissertation (defended August, 2014) develops an articulatory phonology model (for more information, see the more detailed description below) linking the phonology and phonetics of handshapes in American Sign Language (asl ), which was validated against data on handshape variation. On top of handshape variation, my dissertation includes detailed analyses of temporal information of the fingerspelling of native asl signers.